Collections and benchmarks¶
You can combine tasks and runs into collections, to run experiments across many tasks at once and collect all results. Each collection gets its own page, which can be linked to publications so that others can find all the details online.
Benchmarking suites¶
Collections of tasks can be published as benchmarking suites. Seamlessly integrated into the OpenML platform, benchmark suites standardize the setup, execution, analysis, and reporting of benchmarks. Moreover, they make benchmarking a whole lot easier:
- all datasets are uniformly formatted in standardized data formats
- they can be easily downloaded programmatically through APIs and client libraries
- they come with machine-readable meta-information, such as the occurrence of missing values, to train algorithms correctly
- standardized train-test splits are provided to ensure that results can be objectively compared - results can be shared in a reproducible way through the APIs
- results from other users can be easily downloaded and reused
You can search for all existing benchmarking suites or create your own. For all further details, see the benchmarking guide.
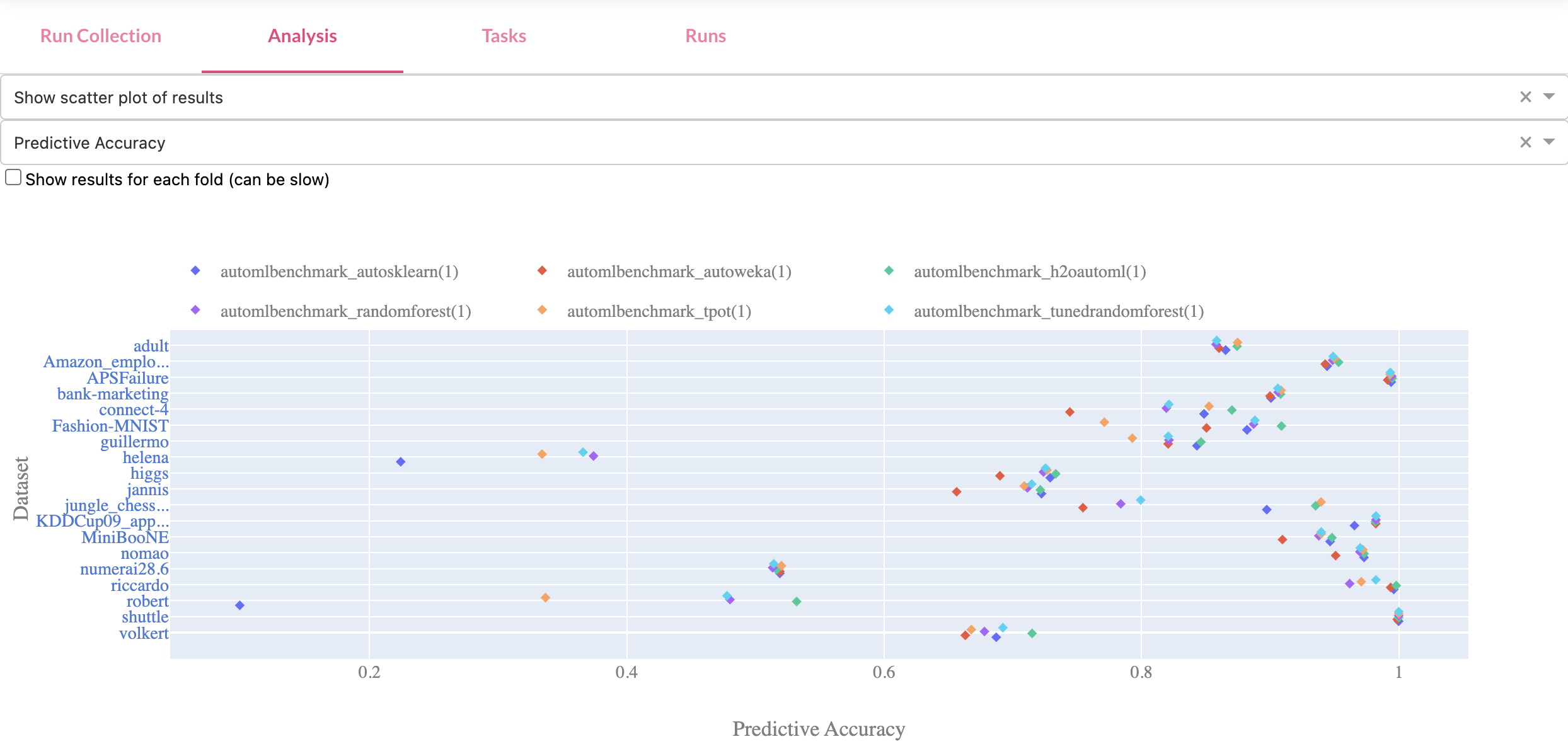
Benchmark studies¶
Collections of runs can be published as benchmarking studies. They contain the results of all runs (possibly millions) executed on a specific benchmarking suite. OpenML allows you to easily download all such results at once via the APIs, but also visualized them online in the Analysis tab (next to the complete list of included tasks and runs). Below is an example of a benchmark study for AutoML algorithms.