Tasks¶
Tasks describe what to do with the data. OpenML covers several task types, such as classification and clustering. Tasks are containers including the data and other information such as train/test splits, and define what needs to be returned. They are machine-readable so that you can automate machine learning experiments, and easily compare algorithms evaluations (using the exact same train-test splits) against all other benchmarks shared by others on OpenML.
Collaborative benchmarks¶
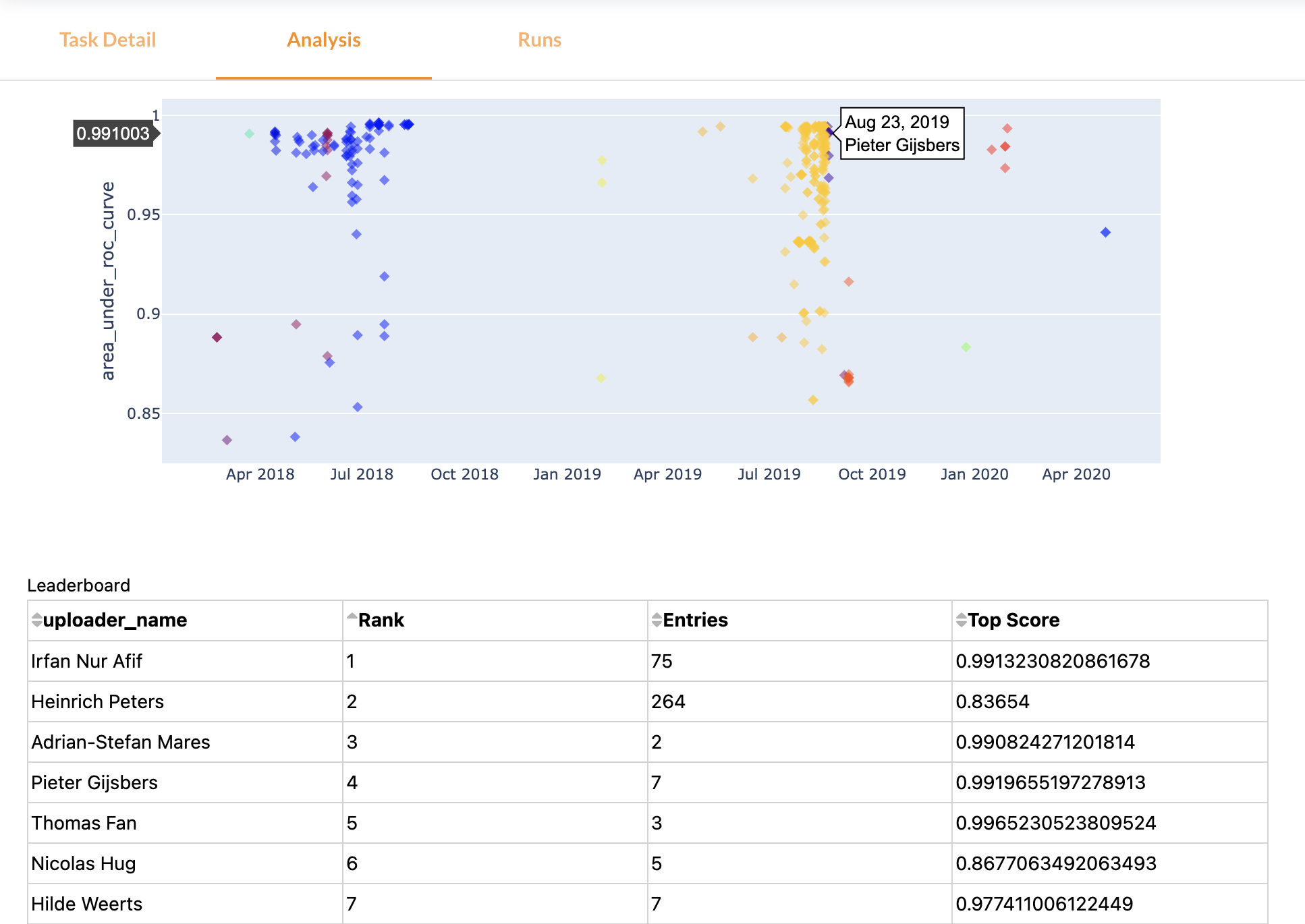
Tasks are real-time, collaborative benchmarks (e.g. see MNIST below). In the Analysis tab, you can view timelines and leaderboards, and learn from all prior submissions to design even better algorithms.
Discover the best algorithms¶
All algorithms evaluated on the same task (with the same train-test splits) can be directly compared to each other, so you can easily look up which algorithms perform best overall, and download their exact configurations. Likewise, you can look up the best algorithms for similar tasks to know what to try first.
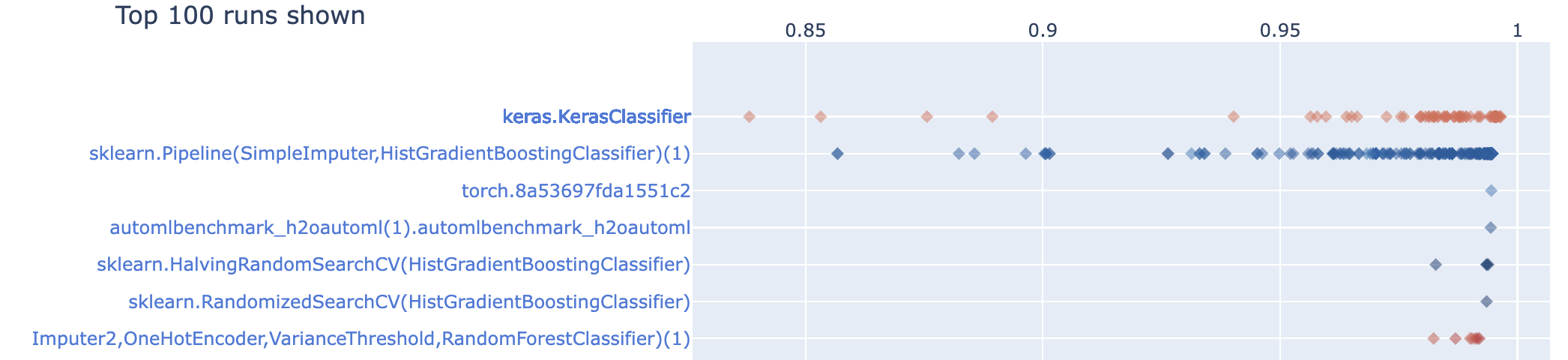
Automating benchmarks¶
You can search and download existing tasks, evaluate your algorithms, and automatically share the results (which are stored in a run). Here's what this looks like in the Python API. You can do the same across hundreds of tasks at once.
You can create new tasks via the website or via the APIs as well.