Data¶
Discovery¶
OpenML allows fine-grained search over thousands of machine learning datasets. Via the website, you can filter by many dataset properties, such as size, type, format, and many more. Via the APIs you have access to many more filters, and you can download a complete table with statistics of all datasest. Via the APIs you can also load datasets directly into your preferred data structures such as numpy (example in Python). We are also working on better organization of all datasets by topic
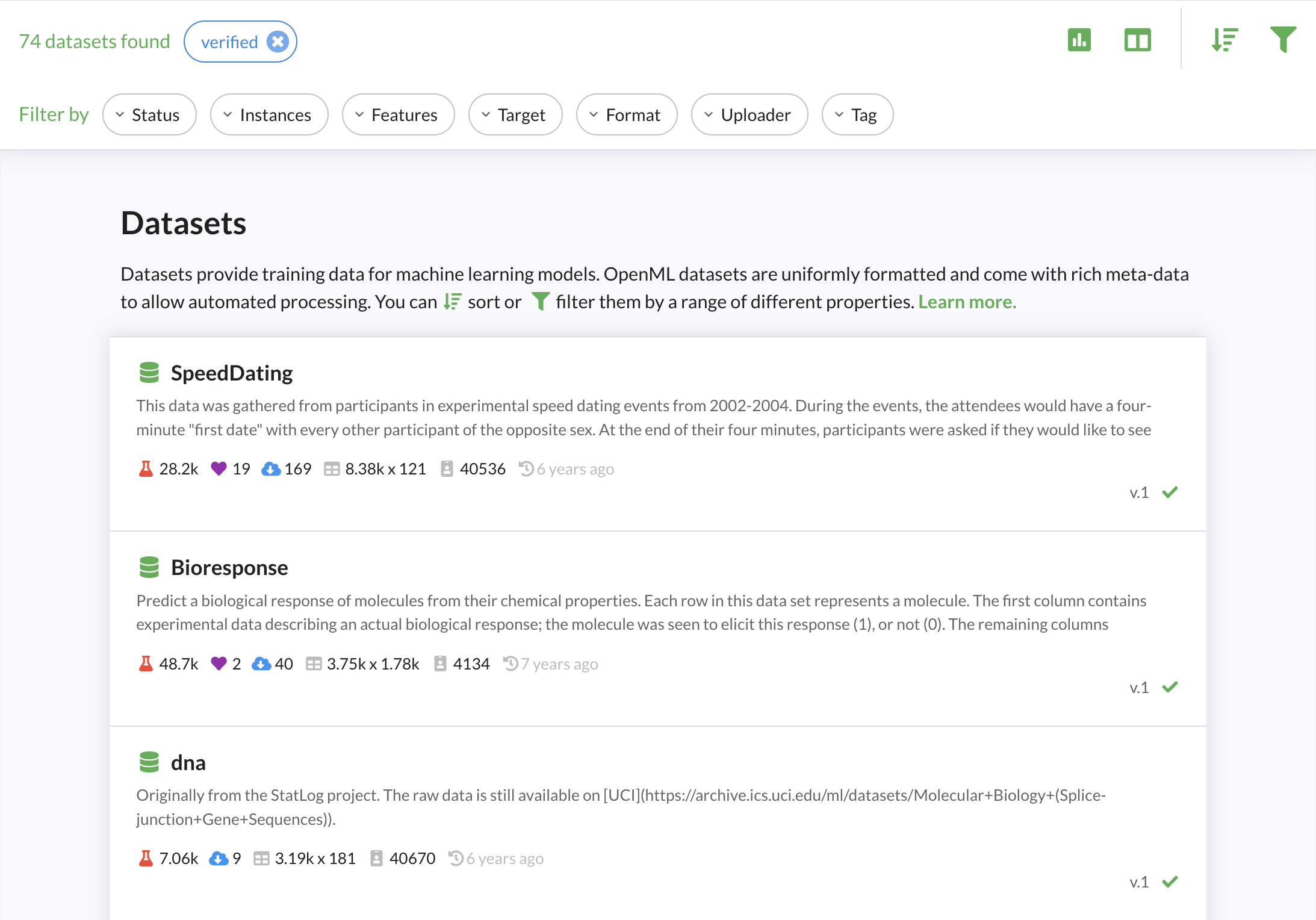
Sharing¶
You can upload and download datasets through the website or though the APIs (recommended). You can share data directly from common data science libraries, e.g. from Python or R dataframes, in a few lines of code. The OpenML APIs will automatically extract lots of meta-data and store all datasets in a uniform format.
Every dataset gets a dedicated page on OpenML with all known information, and can be edited further online.
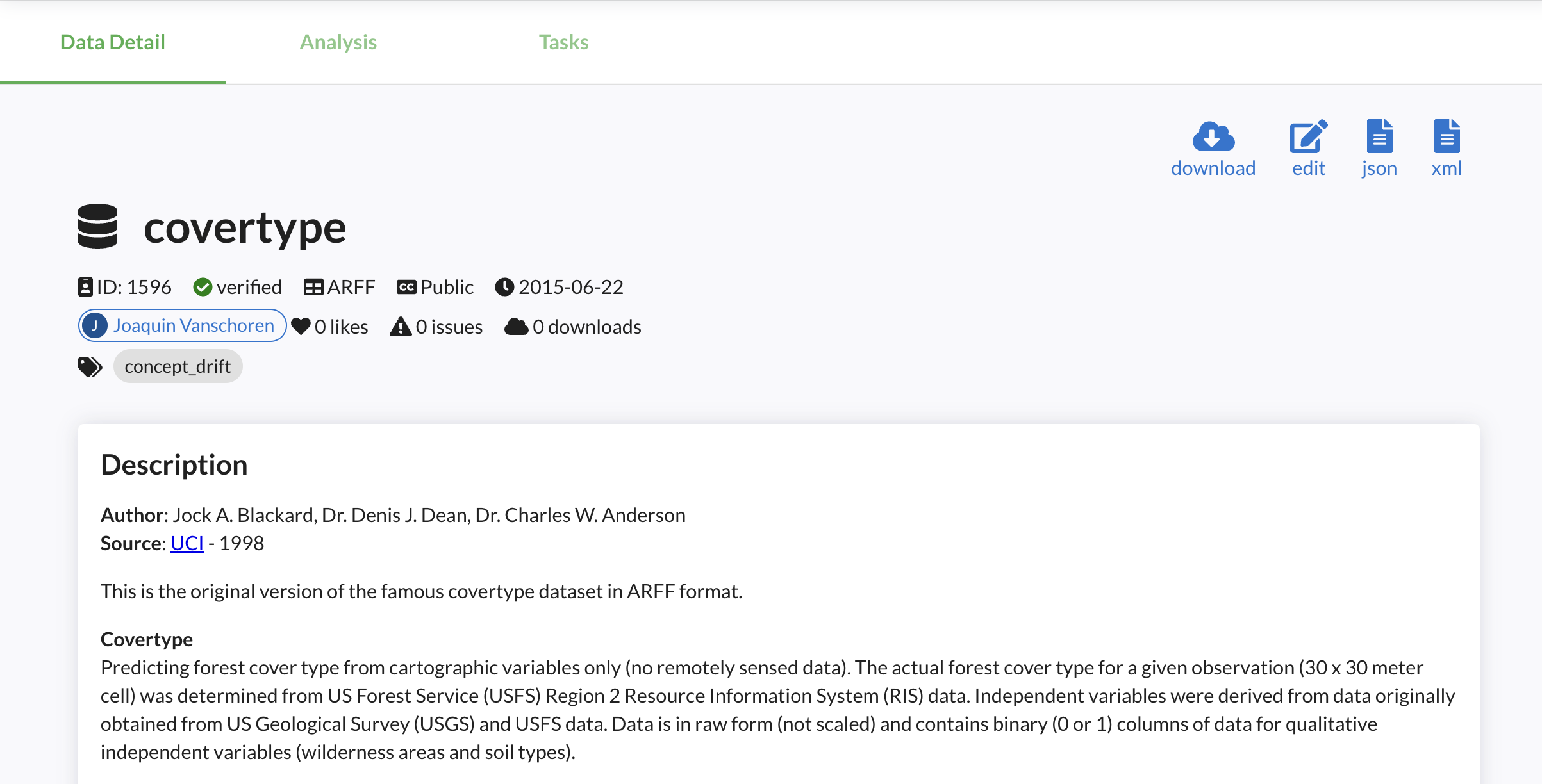
Data hosted elsewhere can be referenced by URL. We are also working on interconnecting OpenML with other machine learning data set repositories
Automated analysis¶
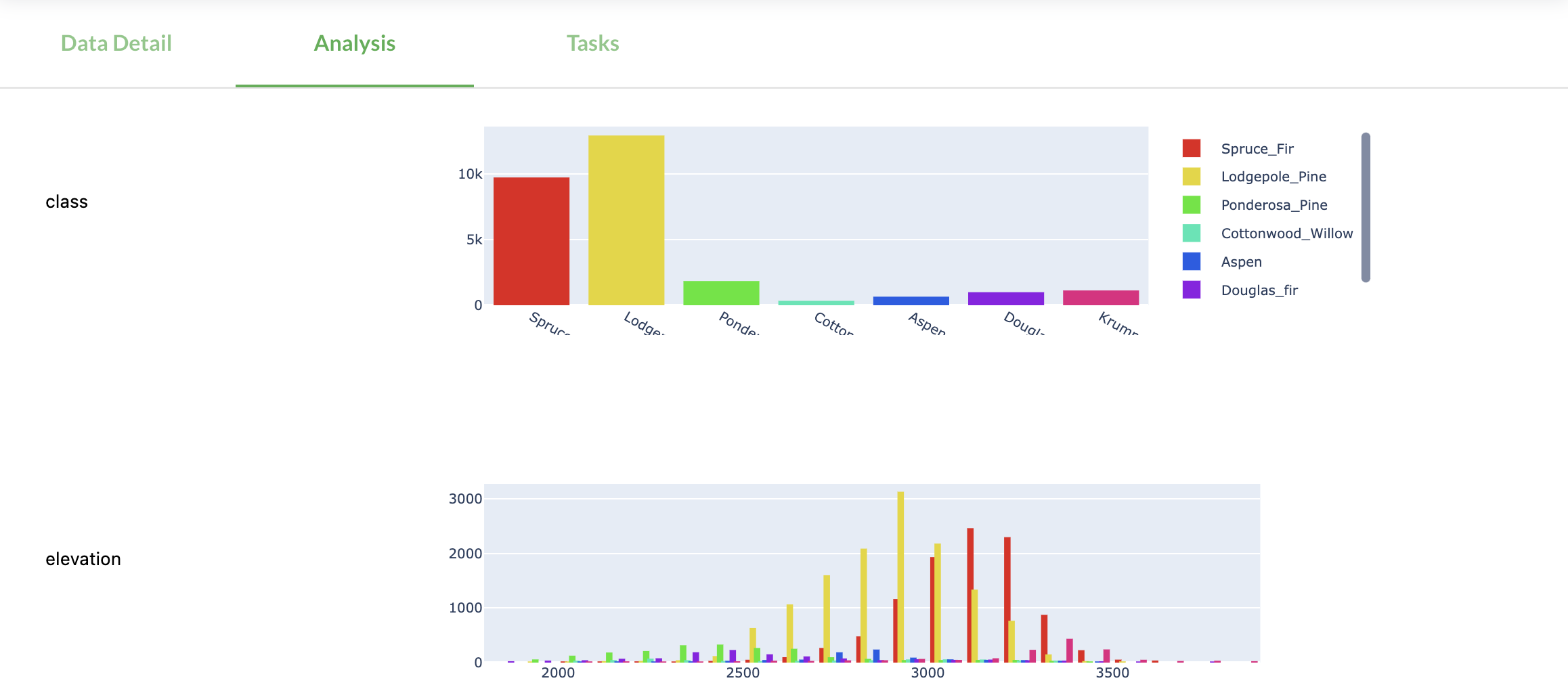
OpenML will automatically analyze the data and compute a range of data quality characteristics. These include simple statistics such as the number of examples and features, but also potential quality issues (e.g. missing values) and more advanced statistics (e.g. the mutual information in the features and benchmark performances of simple models). These can be useful to find, filter and compare datasets, or to automate data preprocessing. We are also working on simple metrics and automated dataset quality reports
The Analysis tab (see image below, or try it live) also shows an automated and interactive analysis of all datasets. This runs on open-source Python code via Dash and we welcome all contributions
The third tab, 'Tasks', lists all tasks created on the dataset. More on that below.
Dataset ID and versions¶
A dataset can be uniquely identified by its dataset ID, which is shown on the website and returned by the API. It's 1596 in the covertype example above. They can also be referenced by name and ID. OpenML assigns incremental version numbers per upload with the same name. You can also add a free-form version_label with every upload.
Dataset status¶
When you upload a dataset, it will be marked in_preparation until it is (automatically) verified. Once approved, the dataset will become active (or verified). If a severe issue has been found with a dataset, it can become deactivated (or deprecated) signaling that it should not be used. By default, dataset search only returns verified datasets, but you can access and download datasets with any status.
Special attributes¶
Machine learning datasets often have special attributes that require special handling in order to build useful models. OpenML marks these as special attributes.
A target attribute is the column that is to be predicted, also known as dependent variable. Datasets can have a default target attribute set by the author, but OpenML tasks can also overrule this. Example: The default target variable for the MNIST dataset is to predict the class from pixel values, and most supervised tasks will have the class as their target. However, one can also create a task aimed at predicting the value of pixel257 given all the other pixel values and the class column.
Row id attributes indicate externally defined row IDs (e.g. instance in dataset 164). Ignore attributes are other columns that should not be included in training data (e.g. Player in dataset 185). OpenML will clearly mark these, and will (by default) drop these columns when constructing training sets.