Flows¶
Flows are machine learning pipelines, models, or scripts. They are typically uploaded directly from machine learning libraries (e.g. scikit-learn, pyTorch, TensorFlow, MLR, WEKA,...) via the corresponding APIs. Associated code (e.g., on GitHub) can be referenced by URL.
Analysing algorithm performance¶
Every flow gets a dedicated page with all known information. The Analysis tab shows an automated interactive analysis of all collected results. For instance, below are the results of a scikit-learn pipeline including missing value imputation, feature encoding, and a RandomForest model. It shows the results across multiple tasks, and how the AUC score is affected by certain hyperparameters.
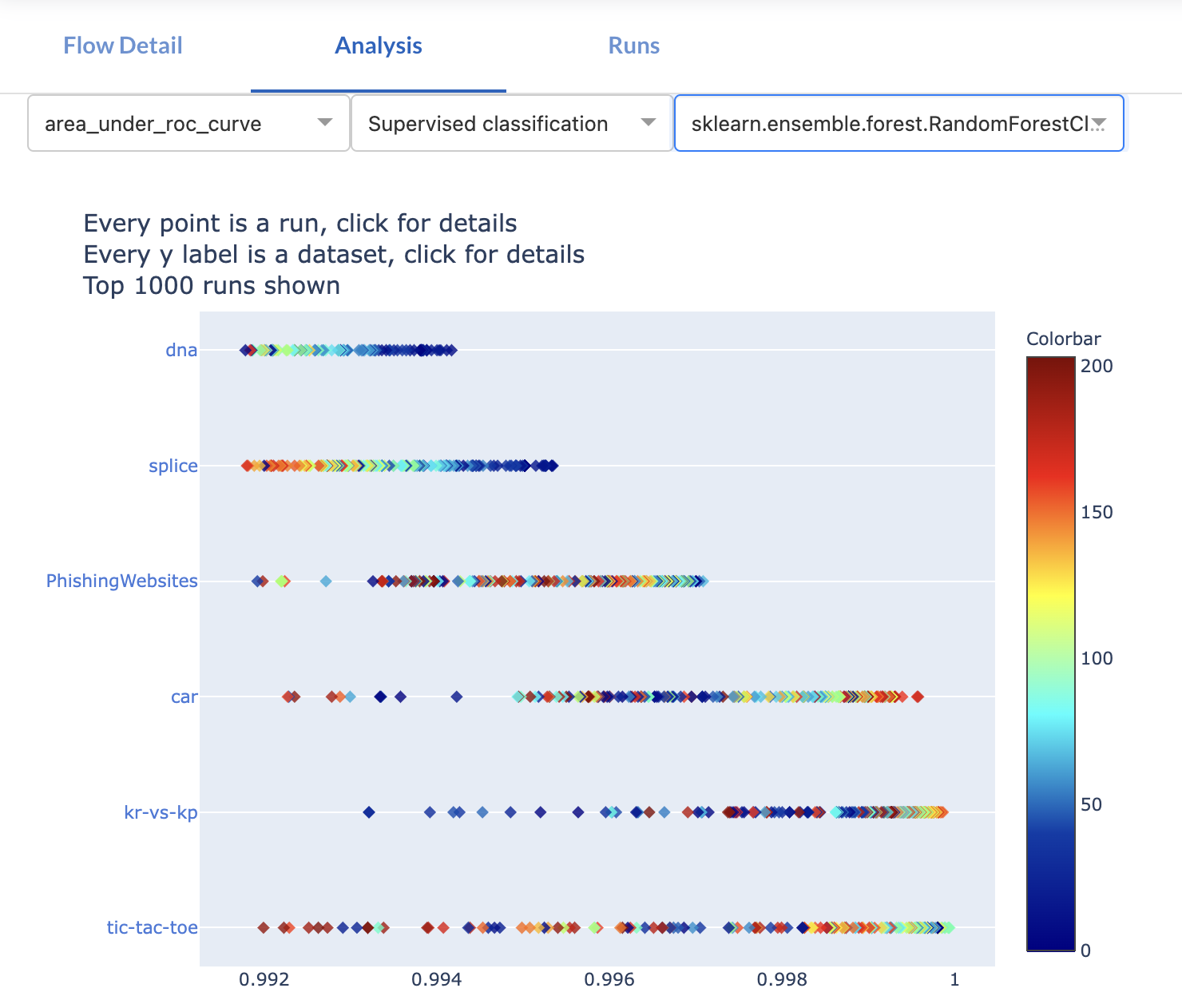
This helps to better understand specific models, as well as their strengths and weaknesses.
Automated sharing¶
When you evaluate algorithms and share the results, OpenML will automatically extract all the details of the algorithm (dependencies, structure, and all hyperparameters), and upload them in the background.
Reproducing algorithms and experiments¶
Given an OpenML run, the exact same algorithm or model, with exactly the same hyperparameters, can be reconstructed within the same machine learning library to easily reproduce earlier results.
Note
You may need the exact same library version to reconstruct flows. The API will always state the required version. We aim to add support for VMs so that flows can be easily (re)run in any environment